データウェアハウス vs データマート vs データレイク
データレイクとデータウェアハウスという言葉はしばしば混同され、時には同じ意味で使われることもある。実際、どちらも巨大なデータセットを保存するために使用されるが、データレイクとデータウェアハウスは異なるものである(補完し合うこともできる)。
- データレイクとは、構造化データ、半構造化データ、非構造化データなど、あらゆる種類のデータを含むことができる巨大なデータプールである。
- データウェアハウスとは、特定の目的のためにすでに処理された、構造化され、フィルタリングされたデータのためのリポジトリである。言い換えれば、データウェアハウスはよく整理され、よく定義されたデータを含んでいる。
- データマート - データウェアハウスのサブセットで、サプライチェーン管理アプリケーションのような特定の目的のために特定の企業のビジネスユニットによって使用される。
データレイクという言葉の発案者であるジェームズ・ディクソンは、その違いを例えで説明している:「データマートをペットボトル入りの水の貯蔵庫と考えるなら、データレイクはより自然な状態の大きな水域である。データレイクのコンテンツは水源から流れ込んできて湖を満たし、湖の様々なユーザーが調べに来たり、飛び込んだり、サンプルを取ったりすることができる。"
データレイクはデータウェアハウスと組み合わせて使うことができる。例えば、データレイクをデータウェアハウスのランディングリポジトリやステージングリポジトリとして使用することができます。データウェアハウスやその他のデータ構造にデータを投入する前に、データレイクを使用してデータをキュレートまたはクレンジングすることができます。
キュレーションされていないデータレイクは、データにガバナンスや品質決定が適用されないままデータ沼と化す危険性があり、収集されたデータから下される意思決定の妥当性を信頼することが難しくなるような方法で、質の異なるデータを「混濁」させることで、データを収集する価値を根本的に低下させる。
次の図は、典型的なデータレイクのテクノロジースタックを表している。データレイクには、スケーラブルなストレージとコンピューティング・リソース、データを管理するためのデータ処理ツール、データサイエンティスト、ビジネスユーザー、技術担当者向けの分析・レポートツール、一般的なデータガバナンス、セキュリティ、運用システムが含まれる。
データレイクは企業のデータセンターでもクラウドでも導入できる。初期の導入企業の多くは、オンプレミスでデータレイクを導入しました。データレイクが普及するにつれ、多くの主流採用企業は、価値実現までの時間を短縮し、TCOを削減し、ビジネスの俊敏性を向上させるために、クラウドベースのデータレイクに注目しています。
オンプレミスのデータレイクはCAPEXとOPEXに集約される
コモディティサーバーとローカル(内部)ストレージを使用して、企業のデータセンターにデータレイクを実装することができます。今日、ほとんどのオンプレミスデータレイクは、データプラットフォームとして、一般的なハイパフォーマンスコンピューティングフレームワークであるHadoopの商用版またはオープンソース版を使用している。(TDWIの調査では、回答者の53%がデータプラットフォームとしてHadoopを使用しており、リレーショナルデータベース管理システムを使用しているのはわずか6%だった)。
数百台、数千台のサーバーを組み合わせて、スケーラブルで弾力性のあるHadoopクラスターを構築し、膨大なデータセットを保存・処理することができます。下図は、Apache Hadoop上のオンプレミスデータレイクのテクノロジースタックを示しています。
技術スタックには以下が含まれる:
オンプレミスのデータレイクは、高いパフォーマンスと強固なセキュリティを提供しますが、導入、管理、保守、スケールが高価で複雑なことで知られています。オンプレミス型データレイクのデメリットは以下の通りです:
長引くインストール
データレイクを自社で構築するには、膨大な時間と労力、コストがかかる。システムの設計とアーキテクチャー、セキュリティと管理システム、ベストプラクティスの定義と導入、コンピュート、ストレージ、ネットワークインフラの調達、立ち上げ、テスト、すべてのソフトウェアコンポーネントの特定、インストール、設定が必要だ。オンプレミスのデータレイクを本番稼働させるには、通常数カ月(多くの場合1年以上)かかる。
高CAPEX
多額の設備投資を先行させることで、ROIが低く、投資回収期間が長い、偏ったビジネスモデルになってしまいます。サーバー、ディスク、ネットワーク・インフラはすべて、ピーク時のトラフィック需要や将来の容量要件を満たすために過剰に設計されているため、アイドル状態のコンピューティング・リソースや未使用のストレージやネットワーク容量に対して常にコストを支払うことになります。
高いOPEX
電力、冷却、ラックスペースの経常的な費用、毎月のハードウェア・メンテナンスとソフトウェア・サポート費用、継続的なハードウェア管理費用など、すべてが高額な機器運用費用につながる。
ハイリスク
事業継続性の確保(セカンダリーデータセンターへのライブデータの複製)は、ほとんどの企業にとって手の届かない高価な提案である。多くの企業はデータをテープやディスクにバックアップしている。大災害が発生した場合、システムを再構築して業務を復旧させるには数日から数週間かかることもある。
複雑なシステム管理
オンプレミスのデータレイクの運用は、貴重な(そして高価な)IT要員をより戦略的な取り組みから逸脱させるリソース集約的な提案である。
クラウドデータレイクが設備コストと複雑さを解消
データレイクをパブリッククラウドに実装することで、設備費用や煩わしさを回避し、ビッグデータへの取り組みを加速することができます。クラウドベースのデータレイクの一般的な利点は以下の通りです:
価値実現までの時間の短縮
インフラの設計作業やハードウェアの調達、インストール、立ち上げ作業を省くことで、ロールアウト期間を数ヶ月から数週間に短縮することができます。
CAPEXなし
先行投資による資本支出を回避し、経費をビジネス要件に合わせ、資本予算を他のプログラムに振り向けることができる。
設備運営費なし
継続的な設備運用費(電力、冷却、不動産)、ハードウェアの年間保守料、定期的なシステム管理コストを削減できる。
即時かつ無限のスケーラビリティ
オンデマンドでコンピュートとストレージの容量を追加できるため、急速に進化するビジネス要件に対応し、顧客満足度を向上させることができます(業務上の要件に迅速に対応)。
独立したスケーリング
内部ストレージを備えたサーバーに依存するオンプレミスのHadoop実装とは異なり、クラウド実装では、コストを最適化し、リソースを最大限に活用するために、コンピュートとストレージの容量を独立して拡張できます。
より低いリスク
地域間でデータを複製して耐障害性を向上させ、大災害が発生した場合でも継続的な可用性を確保することができます。
簡素化されたオペレーション
クラウド・プロバイダーが物理インフラを管理するため、ITスタッフはビジネスをサポートする戦略的業務に専念できる。
第一世代のクラウドストレージサービスはデータレイクにはコストがかかりすぎ、複雑すぎる
オンプレミスのデータレイクに比べ、クラウドベースのデータレイクはデプロイ、スケール、運用がはるかに簡単でコストもかからない。とはいえ、AWS S3、Microsoft Azure Blob Storage、Google Cloud Platform Storageのような第一世代のクラウドオブジェクトストレージサービスは、本質的にコストが高く(多くの場合、オンプレミスのストレージソリューションと同じくらい高い)、複雑だ。多くの企業は、データレイク構想のために、よりシンプルで手頃なストレージサービスを求めている。第一世代のクラウドオブジェクトストレージサービスの限界は以下の通りだ:
高価で分かりにくいサービス・ティア
レガシークラウドベンダーは、いくつかの異なるタイプ(ティア)のストレージサービスを販売している。各階層は、アクティブデータ用のプライマリストレージ、ディザスタリカバリ用のアクティブアーカイバリストレージ、長期データ保持用の非アクティブアーカイバリストレージなど、明確な目的を意図している。それぞれに独自のパフォーマンスと回復力特性、SLA、料金体系がある。複数の価格変動要因を持つ複雑な料金体系は、賢明な選択、コスト予測、予算管理を困難にしている。
ベンダーロックイン
各サービスプロバイダーは独自のAPIをサポートしている。既存のストレージ管理ツールやアプリを書き換えたり、入れ替えたりしなければならない。さらに悪いことに、レガシー・ベンダーはデータをクラウドから移動させるために過大なデータ転送(イグレス)料金を請求する。
階層型ストレージサービスに注意
第一世代のクラウド・ストレージ・プロバイダーは、分かりにくい階層型のストレージ・サービスを提供している。各ストレージ階層は特定の種類のデータ向けで、パフォーマンス特性、SLA、料金プラン(複雑な料金体系を持つ)がそれぞれ異なる。
各ベンダーのポートフォリオは微妙に異なるが、これらの階層サービスは一般的に3つの異なるクラスのデータに最適化されている。
アクティブデータ
オペレーティング・システム、アプリケーション、ユーザーがすぐにアクセスできるライブ・データ。アクティブ・データは頻繁にアクセスされ、読み取り/書き込みの性能要件が厳しい。
アクティブ・アーカイブ
時折アクセスされるデータで、オンラインで即座に利用可能なもの(オフラインまたはリモートのソースから復元および再加湿されない)。例えば、迅速なディザスタリカバリのためのバックアップデータや、急遽アクセスされる可能性のある大容量のビデオファイルなどです。
非アクティブ・アーカイブ
アクセス頻度の低いデータ。例としては、規制遵守のために長期にわたって維持されているデータなどがある。歴史的に、非アクティブデータはテープにアーカイブされ、オフサイトに保管される。
特定のアプリケーションに最適なストレージクラス(および最適な価値)を特定することは、レガシーなクラウドストレージプロバイダーでは本当に難しいことだ。例えばMicrosoft Azureは、4つの異なるオブジェクト・ストレージ・オプションを提供している:General Purpose v1、General Purpose v2、Blob Storage、Premium Blob Storageである。各オプションには独自の価格設定とパフォーマンス特性がある。また、オプションの一部(すべてではない)は、SLAと料金が異なる3つの異なるストレージ階層をサポートしている:ホットストレージ(頻繁にアクセスされるデータ用)、クールストレージ(頻繁にアクセスされないデータ用)、アーカイブストレージ(めったにアクセスされないデータ用)。多くの選択肢と価格変動要因があるため、十分な情報を得た上で決断を下し、費用を正確に予算化することはほぼ不可能である。
IDrive®e2では、クラウド ストレージはシンプルであるべきだと考えています。分かりにくいストレージ階層や複雑な価格体系を持つ従来のクラウドストレージサービスとは異なり、当社は予測可能で手頃な価格の分かりやすい単一製品を提供し、あらゆるクラウドストレージ要件を満たします。IDrive®e2はアクティブデータ、アクティブアーカイブ、非アクティブアーカイブのどのデータストレージクラスにも使用できます。
データレイク用IDrive®e2ホットクラウドストレージ
IDrive®e2ホットクラウドストレージは、あらゆる目的に対応する非常に経済的で高速かつ信頼性の高いクラウドオブジェクトストレージです。分かりにくいストレージ階層や複雑な価格体系を持つ第一世代のクラウドストレージサービスとは異なり、IDrive® e2は分かりやすく、非常に費用対効果の高い拡張が可能です。IDrive®e2は大量の生データの保存に最適です。
IDrive®e2のデータレイクにおける主な利点は次のとおりです:
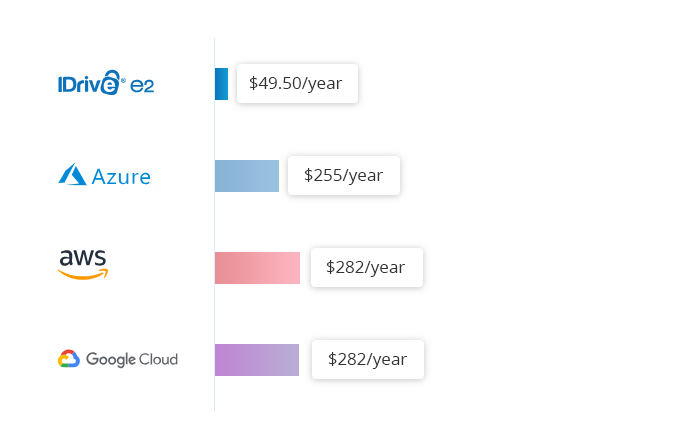
商品価格
IDrive®e2ホットクラウドストレージの料金は一律$0.004/GB/月です。Amazon S3 Standardの$.023/GB/月、Google Multi-Regionalの$.026/GB/月、Azure RA-GRS Hotの$.046/GB/月と比較してください。
AWS、Microsoft Azure、Google Cloud Platformとは異なり、ストレージからデータを取得するための追加料金(イグレス料金)は発生しません。また、APIコールに追加料金を請求することもありません。
優れたパフォーマンス
IDrive®e2の並列化されたシステムアーキテクチャは、第一世代のクラウドストレージサービスよりも高速な読み取り/書き込み性能を実現し、タイムトゥファーストバイトの速度を大幅に向上させます。
堅牢なデータ耐久性と保護
IDrive®e2ホットクラウドストレージは極めて高いデータ耐久性、完全性、セキュリティを実現するように構築されています。オプションのデータ不変性機能は、偶発的な削除や管理上の不慮の事故を防ぎ、マルウェア、バグ、ウイルスから保護し、規制コンプライアンスを向上させます。
Apache Hadoopデータレイク用IDrive®e2 Hotクラウドストレージ
Apache Hadoop上でデータレイクを実行する場合、下図に示すようにIDrive® e2ホットクラウドストレージをHDFSの手頃な代替品として使用することができます。IDrive®e2ホットクラウドストレージはAWS S3 APIと完全な互換性があります。オープンソースApache Hadoopディストリビューションの一部であるHadoop Amazon S3Aコネクタを使用して、Amazon S3やIDrive® e2のような互換性のあるクラウドストレージをさまざまなMapReduceフローに統合することができます。
IDrive®e2ホットクラウドストレージをマルチクラウドデータレイク実装の一部として使用することで、選択の幅を広げ、ベンダーロックインを回避することができます。マルチクラウドアプローチでは、データレイクのコンピュートリソースとストレージリソースを独立して拡張し、最善のプロバイダを使用することができます。
プライベートクラウドをIDrive® e2に直接接続することもできます。第一世代のクラウドストレージプロバイダーとは異なり、IDrive® e2ではデータ転送 (イグレス) 料金を支払う必要はありません。つまり、IDrive®e2から自由にデータを移動することができます。
経済的な事業継続と災害復旧
IDrive®e2は弾力性と高可用性のために地理的に分散された複数のデータセンターでホストされています。以下に示すように、事業継続性、災害復旧、およびデータ保護のためにIDrive® e2地域間でデータを複製することができます。
例えば、3つの異なるIDrive®e2データセンター(地域)にデータを複製することができます:
- IDrive®e2 データセンター 1 はアクティブデータストレージ (プライマリストレージ) 用です。
- IDrive®e2 データセンター 2 をバックアップとリカバリのアクティブアーカイブとして使用します (データセンター 1 にアクセスできない場合のホットスタンバイ)。
- IDrive®e2 Data Center 3は不変のデータストアです (管理上の誤操作、不慮の削除、ランサムウェアからデータを保護するため)。不変データオブジェクトはIDrive® e2を含め、誰によっても削除または変更できません。